El avance continuo de las unidades de procesamiento gráfico o GPUs de alto desempeño y completamente programables de NVIDIA ha llevado a mejoras tremendas en la computación de gráficos 3D y aceleradas por GPU. Esta constante evolución del GPU hace posible las hermosas gráficas que los consumidores disfrutan el día de hoy en juegos y películas, y ademas en avances en la Inteligencia Artificial, el Deep Learning, sistemas de conducción autónomos y un sin numero de aplicaciones de computo-intensivo.
Basada en la revolucionaria arquitectura NVIDIA Pascal, que fue introducida en el GPU GP100 para servidores y datacenters, El próximo GPU de NVIDIA basado en Pascal -el GP104- es el que será responsable de empujar la nueva generación de gráficos DirectX 12 y Vulkan; potenciar los equipos de Realidad Virtual o (VR por sus siglas en ingles), juegos y aplicaciones ademas de dar soporte 4K, 5K, y pantallas HDR con una increíble fidelidad.
La primera tarjeta gráfica que traerá consigo el nuevo GPU GP104 es la GeForce GTX 1080.

Como uno de los lideres en la computación visual, NVIDIA ha sido el pionero de muchas innovaciones en el hardware de GPU y tecnologías de software. Pascal entrega un gran aumento en velocidad y mejoras en la jugabilidad en PC, y las librerías de software GameWorks de NVIDIA permite que desarrolladores puedan implementar experiencias mas interactivas y cinemáticas. El desempeño de la nueva GeForce GTX 1080 combinada con las librerías GameWorks permiten efectos visuales, simulaciones físicas y experiencias VR para la jugabilidad en PC. Los beneficios combinados de la nueva arquitectura Pascal y sus implementaciones, el proceso de manufactura de 16nm FinFET y las ultimas tecnologías de memorias GDDR5X le dan a la GeForce GTX 1080 un 70% mas de rendimiento por sobre la generación anterior de GPUs, como la GeForce GTX 980.
Con 2560 núcleos CUDA corriendo a velocidades sobre los 1600MHz en la GeForce GTX 1080, el GP104 es el GPU más rápido del mundo. Pascal también es una de las arquitecturas mas eficientes del mundo: la GeForce GTX 1080 es 1.5x veces mas eficiente que la GTX 980 y 3x veces mas eficiente que la GTX 780.

La Geforce GTX 1080 no solo permite que los gamers puedan experimentar sus juegos favoritos con gran detalle, simulaciones mejores, y mas cuadros por segundo que antes, si no que también entrega una cantidad mucho mas consistente en la taza de cuadros por segundo y una experiencia de juego mas suave. NVIDIA ha desarrollado una gran cantidad de nuevas tecnologías que están diseñadas para reducir los saltos y otros elementos distractivos que puedan comprometer la experiencia de juego. También se han desarrollado nuevas técnicas de renderizado que están diseñadas para reducir la latencia y mejorar el desempeño en juegos VR. En este articulo encontraras todo lo relacionado con las nuevas tecnologías que NVIDIA ha integrado en la arquitectura Pascal para hacer todo esto posible.
Innovaciones de Pascal
Las demandas en el GPU para los PC entusiastas nunca han sido tan grandes. Resoluciones de pantalla que continúan creciendo, con pantallas 4K y 5K que requieren GPUs extremadamente poderosas (o múltiples GPU) para mantener los FPS estables y con una calidad de imagen alta. Los equipos de VR ahora piden como mínimo que entreguen al menos 90FPS, por cada ojo, y con una latencia muy baja para asegurar una experiencia inmersiva para que se mueva en conjunto con el usuario. La GeForce GTX 1080 fue diseñada con estas tecnologías en mente. Las características principales son:
Arquitectura Pascal
La arquitectura Pascal que se encuentra en la GTX 1080 es la mas eficiente jamas construida. Consiste de 7.2 mil millones de transistores e incluye 2560 núcleos CUDA single-precisión. Con un foco intenso en la manufactura en el chip y en el diseño de la placa, el equipo de ingeniería de NVIDIA logro resultados sin precedentes en frecuencia y eficiencia energética.
16nm FinFET
el GPU GP104 es fabricado en el proceso de 16nm FinFET el cual permite que el chip sea fabricado con mas transistores para que así se puedan activar nuevas características, mas desempeño y una mejora en la eficiencia.
Memoria GDDR5X
GDDR5X provee una mejora en el ancho de banda de memoria por sobre GDDR5, la cual se utilizaba en la generación anterior de GPUs tope de linea de NVIDIA. Corriendo a una taza de transferencia de datos de 10Gbps, la interfaz de memoria de la GTX 1080 entrega un 43% mas de ancho de banda que su predecesora, la GTX 980. Combinado con las mejoras de compresión de memoria, el ancho de banda total efectivo, cuando se le compara con al GTX980 es de 1.7 veces.
Simultaneous Multi-Projection (SMP)
El campo de la tecnologia de pantallas esta efectuando cambios significativos desde los dias de una sola pantalla plana. Reconociendo esta moda, los ingenieros de NVIDIA desarrollaron una tecnologia denominada Simultaneous MultiProjection que por primera vez permite que el GPU simultáneamente mapee un primitivo en hasta dieciséis proyecciones diferentes desde el mismo punto de vista. Cada proyección puede ser mono o estéreo. Esta capacidad permite a la GTX 1080 pueda aproximar precisamente la proyección curva requerida para pantallas VR, los ángulos de proyección múltiple requeridos para configuraciones de pantallas surround y otros usos en el futuro

Arquitectura de GPU – GP104 en profundidad
Los GPUs Pascal están compuestos de diferentes configuraciones de GPCs o Graphics Processing Clusters, SM o Streaming Multiprocessors, y controladores de memoria. Cada SM se encuentra pareado con un Motor PolyMorph que maneja lectura de vértices, teselacion, transformación de viewport, configuración de los atributos de vértices, y corrección perspectiva. El motor PolyMorph del GP104 también incluye una nueva unidad de Multiproyeccion Simultanea que describiremos más adelante. La combinación de un SM mas un Motor PoliMorph es conocida como TPC.

El GPU GP104 abordo de la GeForce GTX 1080 consiste de cuatro GPCs, veinte Streaming Multiprocessors Pascal y ocho controladores de memoria. En la GeForce GTX 1080, cada GPC viene equipado con un motor de rasterizado dedicado y cinco SM. Cada SM contiene 128 núcleos CUDA, 256 KB de capacidad de archivos de registro, 96 KB de unidad de memoria compartida 48 KB de almacenamiento total para el cache L1 y ocho unidades de textura.

El SM es un poderoso multiprocesador paralelo que agenda warps (grupos de 32 hilos) a núcleos CUDA y otras unidades de ejecución dentro del SM. El SM es una de las unidades de hardware mas importantes dentro del GPU, casi todas las operaciones fluyen a través del SM en algún momento en la pipeline de renderizado. Con 20 SMs la GeForce GTX 1080 viene equipada con un total de 2560 núcleos CUDA y 160 unidades de Textura.
También, la GeForce GTX 1080 viene equipada con ocho controladores de memoria de 32-bit (un total de 256-bit). Enlazados a cada controlador de memoria de 32-bit hay ocho unidades ROP y 256KB de cache L2. El chip Gp104 utilizado en la GTX 1080 viene con un total de 64 ROPs y 2048 KB de cache L2.
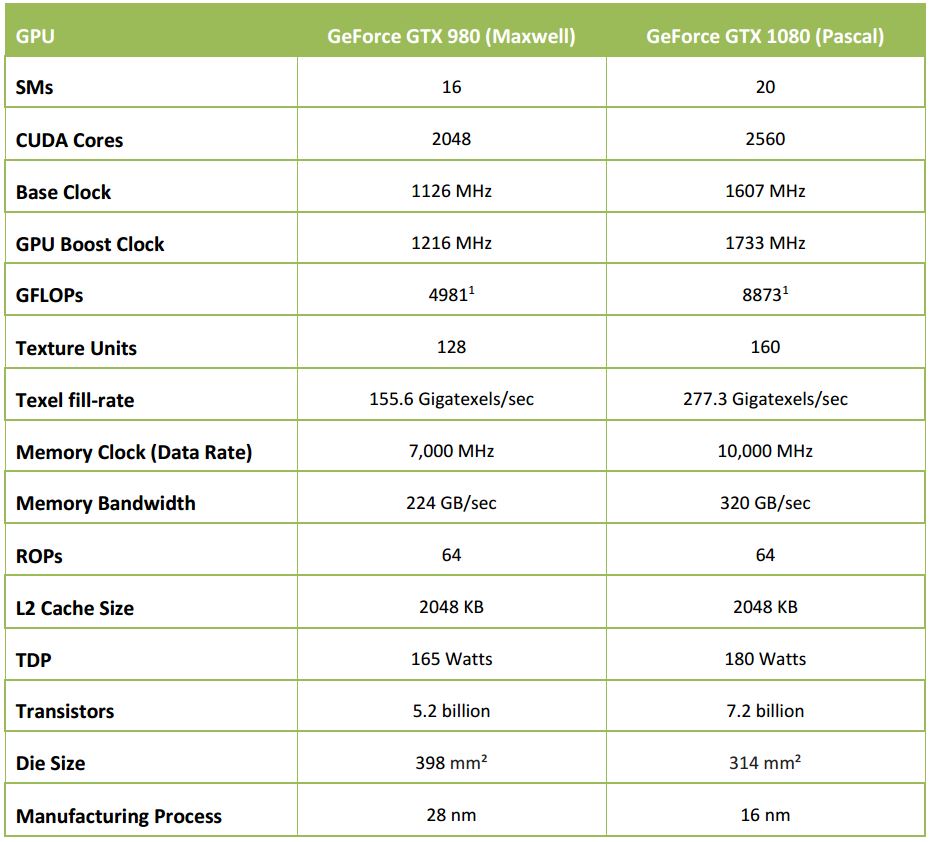
La siguiente tabla provee un alto nivel de comparación entre la Geforce GTX 1080 versus la generación anterior de GeForce.
Arquitectura Pascal: Diseñada para la velocidad.
La artesanía detrás de todos los aspectos del diseño del GPU fue el foco principal en el esfuerzo del desarrollo de Pascal. Como mencionábamos anteriormente, Pascal es el GPU mas eficiente enigmáticamente a la fecha, y no solo por el proceso 16FF, sino que también por la continua mejora del consumo energético en la implementación de GPU. La frecuencia de reloj fue otra área de gran inversión para el equipo de ingeniería de NVIDIA. La frecuencia es establecida no por el camino tiempo promedio de circuito en el diseño, si no que por el camino mas lento dentro de millones de caminos de tiempo. Un diseño cuidadoso y la optimización de caminos críticos es crucial para asegurar que la capacidad del diseño en general no sea restringida. Como resultado del esfuerzo en esta área, la GeForce GTX 1080 entrega un aumento de un 40% en la Frecuencia Boost comparada con una GTX 980, bastante mas arriba en de lo que el proceso de 16nm FF hubiera alcanzado solo.
Memoria GDDR5X
Desde la introducción de las memorias GDDR5 en 2009, los diseñadores de memoria de NVIDIA han estudiado las posibilidades para la próxima generación de tecnologías de memora. GDDR5X es la culminación de ese esfuerzo: GDDR5X es el estándar de interfaz de memoria mas rápido y avanzado de la historia alcanzando velocidades de transferencia de hasta 10 Gbps o casi 100 picosegundos (ps) entre bits de datos. Para poner esa velocidad en contexto de señal, considera que la luz viaja cerca de una pulgada en 100 ps de tiempo. Un circuito IO GDDR5X tiene menos de la mitad de ese tiempo disponible para muestrear un bit cuando llegue, o la información se perderá mientras el bus pasa a un nuevo set de valores.
Para lograr esta operación de alta velocidad, una nueva arquitectura de circuito IO era necesaria y requirió un proyecto de desarrollo de años incorporando los últimos avances en la materia. Cada aspecto del nuevo diseño fue cuidadosamente diseñado para cumplir los estándares exactos de operación de alta frecuencia. Con esto, también se lograron mejoras de desempeño energético a través de la combinación de estas ventajas de circuitería, el bajo voltaje de 1.35V como estándar de GDDR5X y un nuevo proceso tecnológico, resultaron en el mismo consumo eléctrico a un 43% mas de frecuencia.
Ademas, el “canal” entre el die del GPU y el die de la memoria tuvieron que ser diseñados con una gran atención al detalle. la velocidad de operación de la interfaces es determinada solamente por la velocidad de la señal mas débil del bus. Cada señal entre el GPU y el die de memoria fue cuidadosamente estudiada junto con el camino completo fuera del GPU, a través del empaque, hacia la placa y sobre el die de la memoria, con atención a la perdida de canal, crosstalk y discontinuidades que pudieran degradar la señal.
En total, las mejoras de circuito y canal descritas anteriormente no solamente permiten que GDDR5X funcione a 10Gbps, si no que también proveen beneficios que serán útiles para otros productos que utilicen memorias GDDR5X.
Las siguientes imágenes muestran algunos elementos de diseño, incluyendo el diseño IO del circuito, un modelo extraído de un camino de una señal, en amarillo, desde el GPU (arriba a la izquierda) hacia los pads de DRAM (abajo a la derecha) en el nuevo diseño de la placa de la GeForce GTX 1080.

Compresión de memoria mejorada
Como las GPUs anteriores, el subsistema de memorias de la GeForce GTX 1080 utiliza técnicas de compresión de memoria sin perdida para reducir la demanda de ancho de banda de DRAM. La reducción del ancho de banda entregada por la compresión de memoria provee un numero de beneficios:
- Reduce la cantidad de datos escritos en memoria
- Reduce la cantidad de datos transferidos desde memoria al cache L2; efectivamente entregando un incremento en capacidad para el cache L2, ya que las baldosas comprimidas (un bloque de framebuffer de pixeles o muestreos) tiene una huella de memoria más pequeña que una baldoza no comprimida.
- Reduce la cantidad de datos transferidos entre clientes como las Unidades de Textura y el frame buffer.
La linea de compresión del GPU tiene un numero diferente de algoritmos que inteligentemente determinan la forma mas eficiente de comprimir información. Uno de los algoritmos mas importante es el la compresión de color delta. Con la compresión delta de color, el GPU calcula las diferencias entre pixeles en un bloque y almacena el bloque como un ser de pixeles de referencia ademas de los valores delta de referencia. Si los valores deltas son menores, entonces solo un par de bits por pixel son necesarios. Si el empaque en conjunto de valores de referencia y valores delta resultan en menos de la mitad del tamaño de almacenamiento descomprimido, entonces la compresión de color delta es exitosa y la información es almacenada en la mitad del tamaño (compresión 2:1).
La GeForce GTX 1080 incluye la capacidad de compresión de color delta mejorada que ofrece:
- La compresión 2:1 ha sido mejorada para que sea mas efectiva mas seguido.
- Un nuevo modo de compresión 4:1 ha sido agregado para cubrir casos onde los pixeles deltas son muy pequeños y son posibles de empacarse en ¼ del tamaño original.
- Un nuevo modo de compresión 8:1 combina la compresión constante de color 4:1 de bloques de 2×2 pixeles con compresión 2:1 de los deltas entre esos bloques.

La siguiente captura de Project Cars muestra el beneficio de la compresión de color de Pascal. Las partes de la escena que pueden ser comprimidas son reemplazadas con magenta. Mientras que Maxwell era capaz de comprimir bastante de la escena, mucha de la vegetación y partes del auto no podían ser comprimidas. Con Pascal, muy poco deja de ser sin compresión.

Como resultado de las mejoras en compresión de memoria, la GTX 1080 es capas de reducir significativamente el numero de bytes que tienen que ser extraídos de memoria por cuadro. Esta reducción en bytes se traduce en un 20% adicional de ancho de banda efectivo y cuando se le combina con la memoria GDDR5X, esto hace que se entregue un aumento de 1.7 veces el ancho de banda que entregaba la GTX 980.

Computo Asincronico
Actualmente, las cargas de trabajo en la jugabilidad son incrementalmente complejas, con múltiples-independientes, cargas de trabajo asincronicas, que, finalmente, trabajan en conjunto para contribuir a la imagen renderizada. Algunos ejemplos de computo asincronico son:
- Procesamiento de audio y físicas basadas en GPU
- Postprocesado de cuadros renderizados
- Timewarp asincrónico, una técnica usada en VR para regenerar un frame final basado en la posición de la cabeza justo antes de el scanout de la pantalla, interrumpiendo el renderizado del siguiente cuadro para hacerlo.
Estas cargas de trabajo asincronicas crean dos nuevos escenarios a considerar en una arquitectura de GPU.
El primer escenario involucra sobreponer cargas. Ciertos tipos de cargas no llenan el GPU completamente por si mismas. En estos casos, hay una oportunidad de rendimiento para correr dos trabajos al mismo tiempo, compartiendo el GPU y haciendo que funcione mas eficientemente: por ejemplo, una carga de PhysX corriendo al mismo tiempo con un renderizado gráfico.
Para cargas de trabajo sobrepuestas, Pascal introduce el soporte para “dynamic load balancing” o “balanceo de carga dinámico”. En Maxwell, las cargas de trabajo fueron implementadas con un particionado estático del GPU en un subset que corría gráficas y otro subset que corría computo. Esto es eficiente dado que el balance de trabajo entre dos cargas sean parecidas al ratio de particion. Sin embargo, si el computo toma mas que el flujo de carga gráfico, y ambos necesitan ser completados antes de que otro trabajo pueda ser efectuado y la porción de GPU configurada para correr gráficas se vaya a reposo. Esto puede causar desempeño reducido que puede exceder cualquier beneficio de desempeño que pueda haber sido entregado por correr cargas de trabajo sobrepuestas. El balanceo dinámico de carga por hardware soluciona este problema al permitir que las cargas de trabajo sean llenadas en el resto de la maquina si recursos en reposo están disponibles.
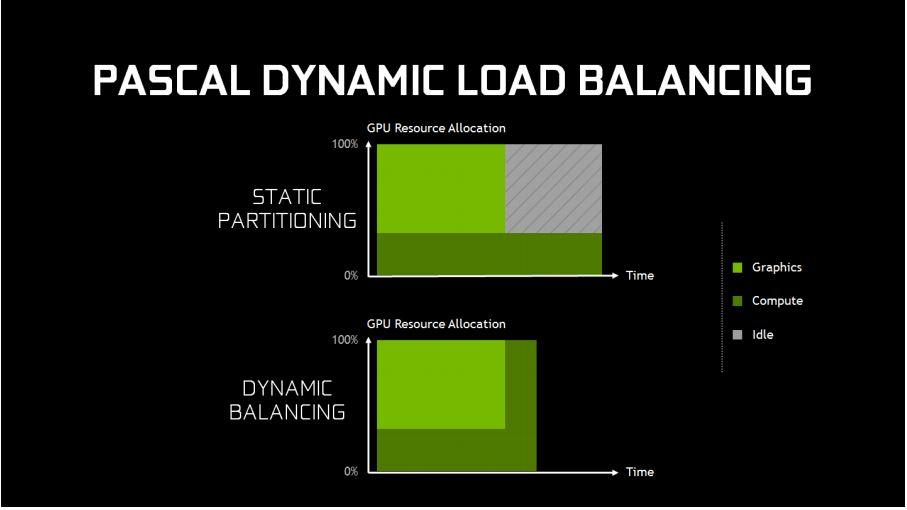
Las cargas de trabajo de tiempo son el segundo escenario de computo asincronico importante. Por ejemplo, una operación asincronica timewarp debe completarse antes de que el scanout comience o un cuadro será botado. En este escenario, el GPU necesita soportar una anticipación rápida y de baja latencia para mover las cargas menos criticas fuera del GPU para que se muevan cargas mas criticas y que puedan ser ejecutadas lo mas rápido posible.
Un solo comando de renderizado de un motor gráfico puede contener potencialmente cientos de llamadas de dibujo, con cada llamada de dibujo conteniendo cientos de triángulos, y cada triangulo conteniendo cientos de pixeles que necesitan ser sombreados y renderizados. Una implementación tradicional de GPU que implementa anticipación a un alto nivel en el flujo gráfico tendría que completar todo este trabajo antes de intercambiar tareas, resultando en un potencial retraso bastante largo.
Para solucionar este problema, Pascal es la primera arquitectura de GPU en implementar Preempción (Anticipación) de nivel de Pixel. Las unidades gráficas de Pascal han sido mejoradas para mantenerse al tanto del progreso intermedio de trabajos de renderizado, para que cuando la anticipación sea solicitada, esas puedan detenerse donde están, guardar la información de contexto a cerca de donde comenzar nuevamente después y anticipar rápidamente. La ilustración siguiente muestra como una petición de anticipación siendo ejecutada.
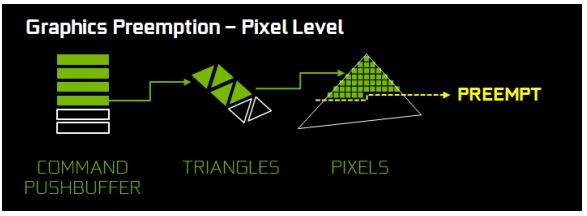
En el comando pushbuffer, tres llamadas de dibujo han sido ejecutadas, una esta en proceso y las otras dos están en espera. La llamada actual tiene seis triángulos, tres han sido procesados, uno esta siendo rasterizado y dos están esperando. El triangulo que se esta rasterizando esta a medio camino. Cuando una petición de anticipación es recibida, el rasterizador, sombreado de triángulos y procesador de comando pushbuffer se detendrán y guardaran su posición actual. Los pixeles que se han rasterizados terminaran de ser sombreados y luego el GPU estará listo para recibir una carga de alta prioridad. El proceso completo de intercambiar a una nueva carga de trabajo puede completarse en menos de 100 microsegundos (μs) después de que el trabajo de sombreado de pixeles sea terminado. Pascal también ha mejorado el soporte de anticipación para cargas de trabajo de computo. La ilustración de abajo muestra la ejecución de una carga de trabajo de computo.
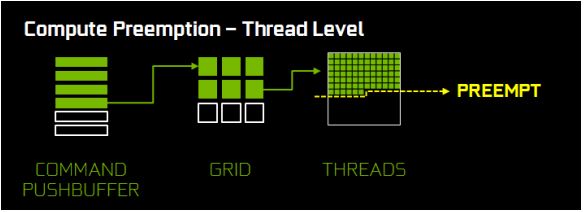
La preempcion (Anticipacion) de nivel de hilo para computo opera similar a lo que vimos anteriormente para gráficas. Las cargas de trabajo son compuestas por múltiples grillas e bloques de hilos, cada grilla contiene varios hilos. Cuando una petición de anticipación es recibida, los hilos que están actualmente corriendo en los SMs son completados. Otras unidades guardan la posición actual para preparase para cuando vuelvan a retomar lo que dejaron antes, y luego el GPU estará listo para nuevas tareas. El proceso completo de intercambiar a una nueva carga de trabajo puede completarse en menos de 100 microsegundos (μs) después de completar las tareas que se corren en el momento. Para cargas de trabajo de juego, la combinación de anticipación de nivel gráfico de pixeles y de nivel de computo de hilos le da a Pascal la habilidad de intercambiar cargas de trabajo de una manera bastante rápida.
Para los computos CUDA, Pascal tambien es capaz de hacer anticipacion:
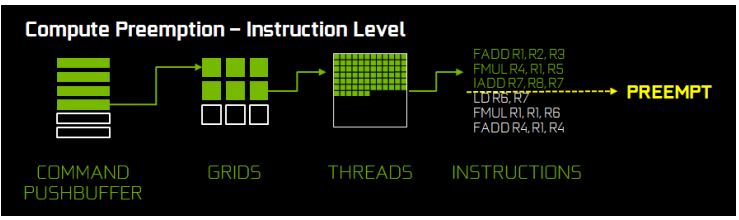
En este modo de operación, cuando la petición de anticipación es recibida, todo el procesamiento de hilos se detiene en la instrucción actual y es intercambiada inmediatamente. Este modo de operación involucra substancialmente mas información de estados, por que todos los registros de cada uno de los hilos que se esta ejecutando, debe ser guardado. Esta es la forma mas robusta para la carga general de trabajos de computo de GPU que puedan tener tiempos de ejecución por hilo substanciales.
Un ejemplo de una aplicación de anticipación en juego es el timewarp asincronico. El lado izquierdo de la ilustración muestra una operación timewarp asincronica con anticipación tradicional de GPU. El proceso ATW corre lo mas tarde posible antes del intervalo de refresco del monitor. Sin embargo, el trabajo ATW tiene que entregarse al GPU con muchos milisegundos de anticipación, por que sin una anticipación fina, hay una variación en el tiempo que le tome anticipar y comenzar la ejecución de ese proceso ATW. En la imagen de la derecha, con anticipación fina, (gráficas de nivel de pixel y ademas anticipación de nivel de hilo), el tiempo de anticipación es mucho mas rápido y determinante, así el trabajo ATW puede ser entregado mucho después mientas que se asegura su finalización antes que se cumpla el limite del refresco del monitor.

Motor de Multi-Proyeccion Simultanea
El bloque de Multi-Proyecction Simultanea es una nueva unidad de hardware, el cual esta ubicada dentro del motor PolyMorph al final del pipeline de geometria y justo en frente de la Unidad de Rasterizado. como su nombre lo dice, la unidad SMP es responsable de generar multiples proyecciones para un solo stream de geometría, mientas este entra al motor SMP por las etapas shader de mas arriba.

El motor SMP es capaz de procesar geometrías a través de 16 proyecciones pre-configuradas, compartiendo el centro de la proyección (el punto de vista), y con hasta dos centros de proyección diferentes, offset a lo largo del eje X. Las proyecciones pueden ser independientemente movidas o rotadas en un eje. Dado que cada primitivo pueda mostrarse en múltiples proyecciones simultáneamente, el motor SMP entrega funcionalidad multi-cast, permitiendo a la aplicación instruirle al GPU que replique la geometría hasta 32 veces (16 proyecciones x 2 centros de proyección) sin la sobrecarga de aplicaciones adicionales ya que la geometría fluye por las lineas.
En todos los escenarios, el procesamiento es acelerado por hardware, y el flujo de datos nunca deja el chip. Dado que la expansión de la multi-proyección sucede después del pipeline de geometría, la aplicación guarda todo el trabajo que de otra forma necesitaría para efectuarse en las etapas de shader de mas arriba . Los ahorros son particularmente importantes en escenarios de geometría pesada, como teselacion, donde correr el pipeline de proceso de geometría múltiples veces (una vez por cada proyección) seria muy costoso. En casos extremos, el motor SMP puede reducir la cantidad requerida de trabajo geométrico hasta 32x. Un ejemplo de aplicación SMP es el soporte optimo de pantallas surround. La forma correcta de renderizar pantallas surround es con diferentes proyecciones para cada uno de los tres monitores, haciendo calzar el angulo. Esto es soportado directamente en solo un paso por el SMP de Pascal, al especificar tres proyecciones separadas, cada una correspondiente al monitor apropiadamente ajustado. Ahora, el usuario tiene la flexibilidad de elegir el ajuste para sus monitores laterales y verá sus gráficas renderizadas con perspectivas geométricas correctas, con un mas amplo campo de visión (FOV). También hay que tener en consideración que una aplicación que utilice SMP para generar imágenes de pantalla surround debe soportar opciones FOV, y también utilizar llamadas API SMP para activar el FOV mas amplio.
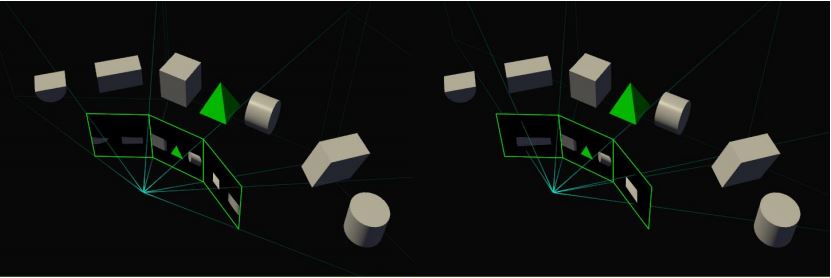
En los casos de que la superficie de proyección no pueda ser exactamente representada con un numero finito de proyecciones, el motor SMP de todas formas podrá entregar ganancias de eficiencia substanciales al generar una aproximación mas cercana a la superficie de proyección.
Interfaz SLI Mejorada.
Los entusiastas confían en que la tecnología SLI de NVIDIA les entregue la mejor de las mejores experiencias de juego a resoluciones y configuraciones al tope. Un ingrediente crítico en la tecnología SLI es el puente SLI, el cual es una interfaz digital que transfiere información de display entre las tarjetas GeForce instaladas en el sistema. Dos de estas interfaces han sido utilizadas históricamente para permitir comunicación entre tres o más GPUS (configuraciones 3Way o 4Way SLI).
La segunda interfaz SLI es requerida para estos escenarios porque todos los GPUs necesitan transferir sus cuadros renderizados al monitor conectado al GPU maestro y en este punto cada interfaz se convierte en independiente.

Comenzando con las GPUs de NVIDIA Pascal, las dos interfaces ahora se encuentran vinculadas para mejorar el ancho de banda entre GPUs. Este nuevo modo dual-link SLI permite que ambas interfaces SLI puedan ser utilizadas en tándem para alimentar una pantalla de alta resolución o múltiples pantallas en Surround.
El modo Dual-Link SLI esta soportado con un nuevo puente SLI llamado SLI HB. Este puente facilita la transferencia de datos de alta velocidad entre GPUs, conectando ambas interfaces SLI. Esta es la mejor forma para lograr frecuencias completas SLI con las GPUs GeForce GTX 1080 corriendo en SLI. (Nota: la GeForce GTX 1080 es compatible con los puentes SLI anteriores, sin embargo, el GPU estará limitado a la máxima velocidad del puente que se utilice.

Utilizando estos nuevos puentes SLI HB, la interfaz SLI de la GeForce GTX 1080 corre a 650MHz, comparada con los 400MHz que se encuentran en las GPUs GeForce anteriores que ocupan los antiguos puentes SLI. Sin embargo, los puentes antiguos funcionarán algo mas rápido cuando se utilicen con GPUs basadas en Pascal. Específicamente, puentes personalizados que incluyan iluminación LED ahora funcionaran a 650MHz cuando sean utilizados con una GTX 1080, tomando ventaja de la velocidad IO de Pascal.

El nuevo sub-sistema SLI que se encuentra en la GeForce GTX 1080 entrega mas del doble del ancho de banda entre GPUs cuando se le compara con la interfaz SLI de las generaciones anteriores. Esto es particularmente importante para altas resoluciones como 4K, 5K y surround. Ya que la GeForce GTX 1080 ahora soporta diferentes tipos de puentes, es importante saber que puentes funcionan mejor dependiendo la necesidad. Abajo se encuentra una tabla con las configuraciones recomendadas:

Con el ancho de banda adicional entregado por la nueva interfaz SLI y el puente SLI HB, el SLI de GeForce GTX 1080 entregará a los gamers una experiencia de juego aun mas fluida comparada con las soluciones anteriores SLI como se muestra en el gráfico a continuación:
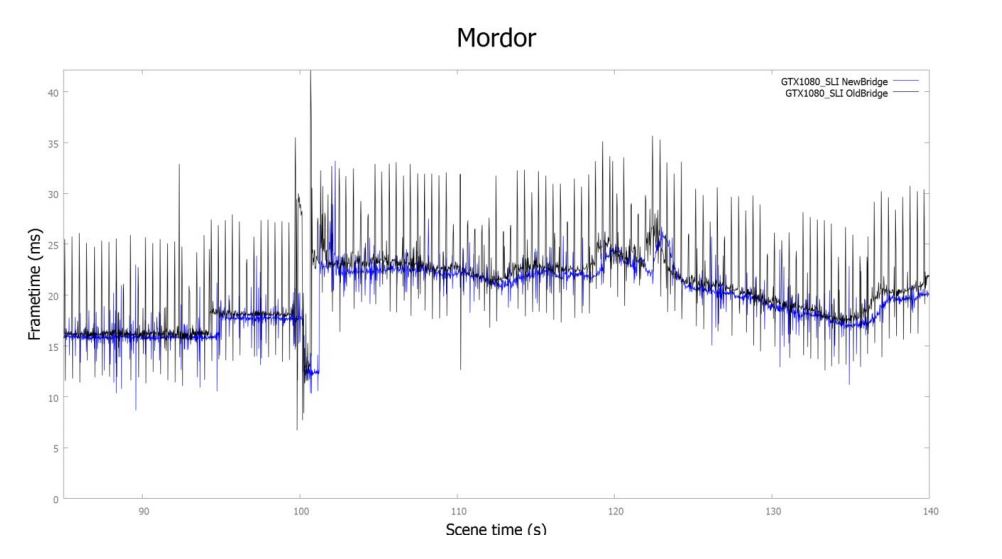
Tiempos de Cuadros por segundo con una GeForce GTX 1080 corriendo Shadow of Mordor a 11520×2160 con el nuevo puente SLI HB (en azul) vs el viejo puente SLI (en negro). Los peaks mas largos del puente viejo indican stuttering.
Nuevos modos Multi GPU
Comparado con APIs anteriores de DirectX, Microsoft ha hecho un gran numero de cambios que tienen impacto en la funcionalidad de Multi-GPU en DirectX 12. En el nivel mas alto, hay dos opciones básicas para que los desarrolladores utilicen multiGPU en hardware NVIDIA con DX12:
- Multi Display Adapter (MDA)
- Linked Display Adapter (LDA)
El modo LDA tiene dos formas: Implicit LDA Mode, el cual NVIDIA utiliza para el SLI, y Explicit LDA Mode, donde los desarrolladores de juegos manejaran la responsabilidad necesaria para que la operación de multiGPU funcione exitosamente. Los modos MDA y LDA han sido desarrollados para entregarle mas control a los desarrolladores mas control.
La siguiente tabla resume los tres modos soportados en GPUs NVIDIA:

En modo LDA, cada memoria de los GPUs puede ser vinculada completamente para ser un gran banco de memoria para el desarrollador (aun que hay algunas excepciones); sin embargo, hay una penalización de desempeño si la información necesita ser ubicada en la memoria de otro GPU, dado que la memoria se accede a través del interior del GPU en comunicación peer-to-peer (como PCIe). En el modo MDA, cada memoria de cada GPU es utilizada independientemente: cada GPU no puede acceder directamente a la memoria del otro.
El modo LDA es destinado para el uso de multo-GPU en sistemas que tienen GPUs similares a si mismas, mientras que el modo MDA tiene menos restricciones – GPUs discretas pueden ser pareadas con GPUs integradas, o GPUs discretas de otros fabricantes- pero el modo MDA requiere que el desarrollador tenga mucho mas cuidado al manejar todas las operaciones necesarias para que los GPUs se comuniquen entre si.
Por defecto el SLI de GeForce GTX 1080 soporta hasta dos GPUs. Los Modos 3-Way y 4-Way SLI ya no serán recomendados. Como los juegos han evolucionado, se ha convertido en algo bastante difícil que estos modos SLI entreguen un desempeño beneficial de escalado para los usuarios. Por ejemplo, muchos juegos se quedaban cortos de CPU al generarse un cuello de botella cuando se corrían en los modos 3-Way o 4-Way SLI, y los juegos están constantemente utilizando técnicas que hacen muy difícil la extracción de paralelismo cuadro-a-cuadro. Ahora, los sistemas aun pueden ser construidos con modos Multi-GPU por software incluyendo:
- MDA o LDA Explicit
- 2-Way SLI + un GPU para PhysX.
Llave entusiasta
Si bien NVIDIA no recomienda los modos 3-Way o 4-Way SLI, todos sabemos que los entusiastas no se quedaran tranquilos… de hecho, algunos juegos seguirán entregando gran escalabilidad mas allá de dos GPUs. Para esta clase de usuarios, se ha desarrollado una “Llave Entusiasta” o “Enthusiast Key” la cual puede ser descargada desde la pagina de NVIDIA y ser cargado para cada GPU. El proceso involucra:
- Correr la app localmente para generar la firma de tu GPU
- Pedir la Enthusiast Key en el sitio web de entusiastas de NVIDIA
- Bajar la llave
- Instalar la llave para desbloquear la función 3-Way y 4-Way SLI.
Los detalles de este proceso estarán disponibles eventualmente en el sitio web de NVIDIA cuando los GPUs GTX 1080 esten en las manos de los usuarios.
Fast Sync
Fast Sync es una alternativa, consciente a la latencia, al Vertical Sync o V-SYNC, que elimina el tearing, mientras permite al GPU renderizar sin restricciones de refresco para reducir latencia.
Cuadros Renderizados – Metodo tradicional
Esta es un gráfico básico de como la renderización de cuadros funciona en un pipeline de gráficas NVIDIA:

El motor del juego es el responsable de generar los cuadros que son enviados a DirectX. El motor del juego también calcula el tiempo de animación; la codificación del cuadro que eventualmente se renderizará. Las llamadas de dibujo e información son comunicadas, el driver de NVIDIA y el GPU las convierten en renderizado, y luego se escupe el cuadro renderizado al frame buffer del GPU. El ultimo paso es escanear el cuadro a la pantalla. Ahora, estamos haciendo las cosas algo diferentes en Pascal.
Juegos de altos FPS (Frames-Per-Second)
Juegos de altos FPS, como Counter-Strike: Global Offensive, se corren a muchos cuadros por segundo el día de hoy en Pascal. La pregunta es: ¿que de bueno es esto?. El día de hoy, hay dos opciones para mostrar el juego: con V-SYNC ON o con V-SYNC OFF.
| V-SYNC ON | V-SYNC OFF | |
|---|---|---|
| Control de Flujo | Backpressure | Ninguno |
| Latencia de Entrada | Alta | Baja |
| Tearing de Cuadros | Ninguno | Tearing |
Si utilizas V-SYNC ON, el pipeline se presuriza hasta el motor del juego y el pipeline completa se ralentiza a la frecuencia de refresco del monitor. Con V-SYNC ON, el monitor básicamente le dice al motor del juego que se relaje, solo por que un solo cuadro se puede ser generado por cada intervalo de refresco del monitor. La ventaja de V-SYNC ON es la eliminación del tearing, pero la desventaja es la latencia. Cuando utilizamos V-SYNC OFF, se le dice a la pipeline que ignore la frecuencia de refresco del monitor y que entregue los cuadros del juego lo mas rápido posible. La ventaja de V-SYNC OFF es baja latencia (ya que no hay presión), pero la desventaja es el tearing. Estas son las opciones que tienen los gamers actualmente y la mayoría de los gamers de eSports juegan con V-SYNC OFF para tomar ventaja de la baja latencia, dándoles una ventaja competitiva. Desafortunadamente, el tearing a altos FPS causa jittering, el cual puede estorbar su juego.
Decoupled Render y Pantalla

NVIDIA ha tomado otra mirada a como el proceso tradicional funciona y, por primera vez, el renderizado y el monitor han sido desvinculados de la pipeline. Esto permite que la etapa de renderizado continuamente genere nuevos cuadros de la información enviada por el motor del juego y driver a velocidad completa, y esos cuadros pueden ser almacenados temporalmente en el frame buffer del GPU.
Cuadros Renderizados – FAST SYNC
NVIDIA ha desvinculado el comienzo de la pipeline de renderizado desde el backend del hardware del monitor. Esto permite muchas formas para manipular el monitor y esto puede entregar nuevos beneficios a los gamers. Fast Sync es una de las primeras aplicaciones de esta propuesta. Con Fast Sync, no hay control de flujo. El motor del juego funciona como si el V-SYNC estuviera desactivado. Y, como no hay presión trasera, la latencia es tan baja como si el V-SYNC estuviera en OFF. Lo mejor es que , no hay tearing, ya que Fast Sync elige que cuadros renderizados terminaran en el monitor. Fas Sync permite que el frente de la pipeline corra lo mas rápido que pueda, y que determine la cantidad de cuadros que se enviaran al monitor, mientras que simultaneamente preservará cuadros enteros para que sean mostrados sin tearing.
| V-SYNC ON | VSYNC OFF | FAST SYNC | |
|---|---|---|---|
| Control de Flujo | Backpressure | Ninguno | Ninguno |
| Latencia de Entrada | Alta | Baja | Baja |
| Tearing de Cuadros | Ninguno | Tearing | Ninguno |
La experiencia que FAST SYNC entrega, dependiendo del frame rate, es casi igual a la claridad del V-SYNC on combinado con la baja latencia de V-SYNC OFF.
Buffers Desacoplados
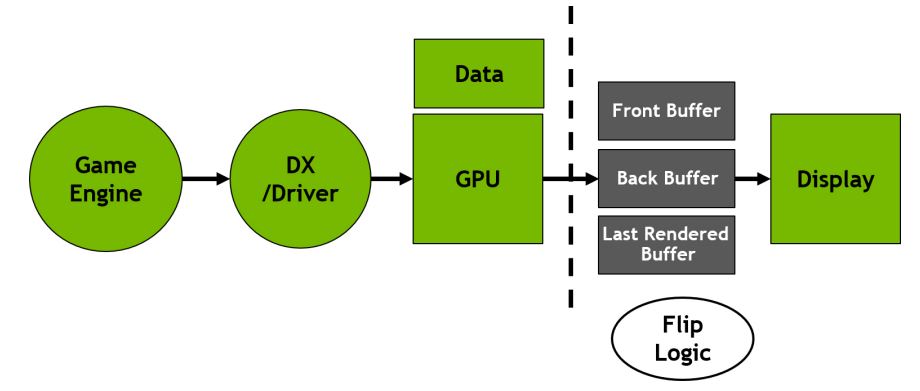
Una forma para pensar sobre Fast Sync es imaginar que tres áreas en el mismo frame buffer han sido ubicadas en tres formas diferentes. Los dos buffers primarios son bastante similares a un VSYNC de doble buffer en las pipelines clásicas de GPU. El Buffer Frontal (FB) es el buffer escaneado hacia la pantalla. Esta es una superficie completamente renderizada. El Buffer Trasero, es el que actualmente se está renderizando y no puede ser escaneado hasta que se complete. Usando el VSYNC tradicional en juegos de alto renderizado, no es bueno para la latencia, dado que el juego debe esperar al intervalo de refresco para dar vuelta el buffer trasero para que se convierta en buffer frontal antes de que otro cuadro pueda ser renderizado en el buffer trasero. Esto ralentiza todo el proceso y agregar buffers traseros solo agrega mas latencia, dado que estos podrían llenarse rápidamente por el renderizado de alta demanda, causando pausas en el motor del juego. Fast Sync introduce un tercer buffer llamado Ultimo Buffer de Renderizado (Last Rendered Buffer o LRB) el cual se utiliza para mantener todos los nuevos cuadros renderizados que se completaron en el Buffer Trasero – en efecto, haber tenido copia mas reciente del buffer trasero – hasta que el buffer delantero haya terminado de escanearse, al punto de que el Ultimo Buffer Renderizado es copiado al buffer frontal y el proceso continua. Las copias actuales del buffer serian ineficientes, así que los buffers son solo renombrados. El buffer que se esta escaneando a la pantalla es el FB, el buffer que se esta renderizando activamente es el BB y el buffer almacenando la copia mas reciente es el LRB. La nueva lógica de cambios en la arquitectura Pascal controla el proceso completo. El proceso típico se vería de la siguiente forma:
- Escanear de FB
- Renderizar a BB
- Cuando el renderizado se completa
- BB se convierte en LRB
- LRB se convierte en BB y el renderizado continua
- Cuando el renderizado se completa
- BB se convierte en LRB
- LRB se convierte en BB y el renderizado continua
- Cuando el renderizado se completa
- BB se convierte en LRB
- LRB se convierte en BB y el renderizado continua
- Cuando el escaneo se completa
- LRB se convierte en FB
- Comienza a escanear desde un nuevo FB
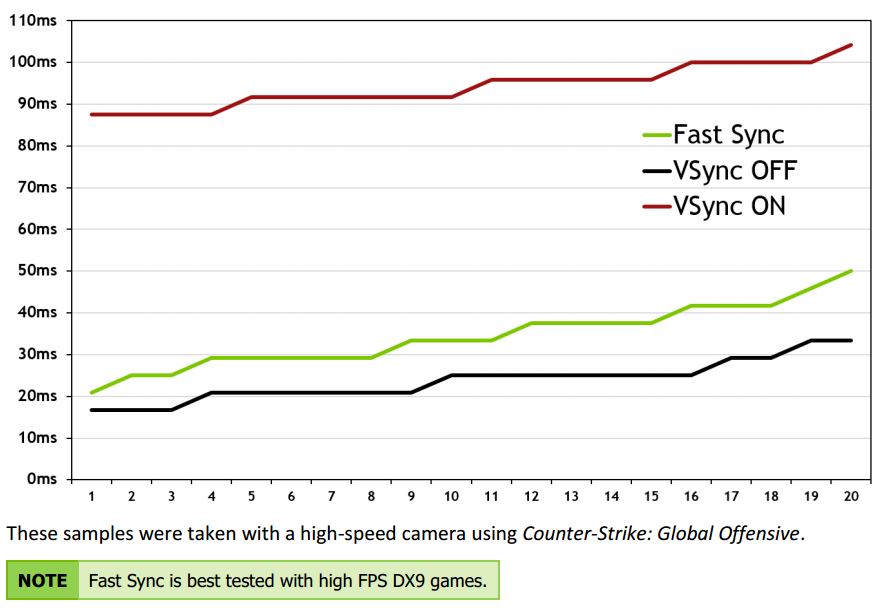
Resultados de latencia Fast Sync
Los datos son convincentes. La latencia es alta con V-SYNC ON. Los gamers de juegos de altos FPS utilizan V-SYNC OFF para tener la mejor respuesta en sus juegos, mientras que pelean con jitter causado por el tearing a altas tasas de cuadros por segundos. Activar Fast Sync entrega ~8ms mas de latencia que V-SYNC OFF, mientras que entrega cuadros completos sin problemas como tearing o jitter.
HDR
Los nuevos monitores HDR (High Dynamic Range) proveen uno de las grandes ventajas en la calidad de pixeles en monitores en los últimos 20 años. El gamut de color BT.2020 cubre hasta el 75% de los colores visibles (hasta un 33% para sRGB) – un aumento de dos veces en el rango de colores. En adición, se estima que los monitores HDR entreguen un peak de brillo mas alto (con paneles LCD sobre los 1000 nits) y una gran relación de contraste (>10:000 a 1).
Con un mayor rango de brillo y colores mas saturados, el contenido HDR imita de forma mas cercana el mundo real: negros mas intensos, y blancos mas brillantes. Variaciones adicionales en el color producen imágenes mas vivas que resaltan: los usuarios finalmente ven el rojo y naranjo en el fuego o una explosión, en vez de verse todo mezclado. Y por que los monitores HDR soportan relaciones de contraste mas altas, los usuarios verán mas detalles en las áreas de escenas claras y oscuras cuando se le compara al SDR que viene en los monitores actuales.

La GeForce GTX 1080 soporta todas las capacidades HDR que tenia Maxwell. El controlador de pantalla es capaz de color 12b, color gamut BT.2020 amplio, SMPTE 2084 (Perceptual Quantization), y HDMI 2.0b 10/12b para 4K HDR. En adición, Pascal introduce nuevas características como:
– 4K@60 10/12b HEVC Decode (para HDR Video)
– 4K@60 10b HEVC Encode (para grabacion HDR o streaming)
– DP1.4-Ready HDR Metadata Transport (para conectar monitores HDR utilizando DisplayPort)

Televisores HDR están disponible hoy, y las características mencionadas anteriormente permitirá que los usuarios puedan disfrutar juegos HDR en sus televisores HDR incluso si su PC no esta conectado directamente al TV, utilizando HDR GameStream, que estará disponible en el futuro cercano.
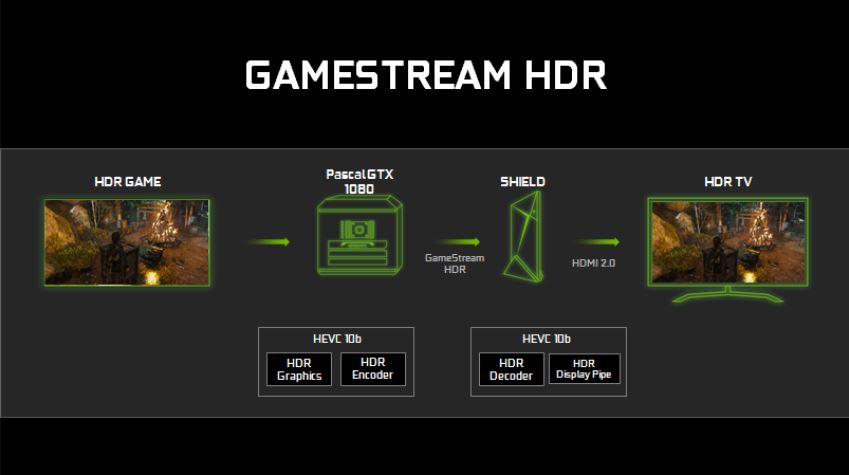
NVIDIA está trabajando con los desarrolladores de juegos para traer HDR a los juegos de PC. NVIDIA le entregará a los desarrolladores APIs y soporte de drivers así como también las guías necesarias para renderizar adecuadamente imágenes HDR que sean compatibles con los nuevos monitores HDR. Como un resultado de este esfuerzo, se vienen próximamente juegos que soportan HDR como Obduction, The Witness, Lawbreakers, Rise of the Tomb Raider, Paragon, The Talos Principle y Shadow Warrior 2.


{kind=link}